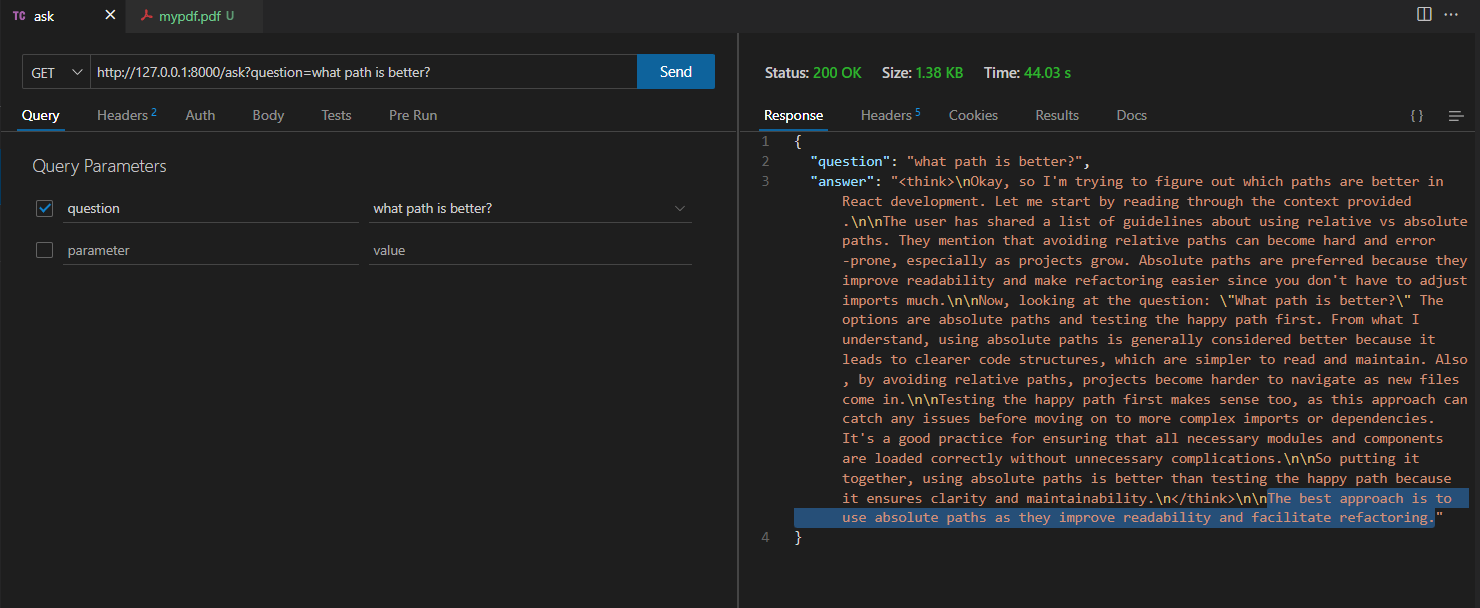
I recently built a lightweight Retrieval-Augmented Generation (RAG) API using FastAPI, LangChain, and Hugging Face embeddings, allowing users to query a PDF document with natural language questions. Here’s the breakdown:
How It Works
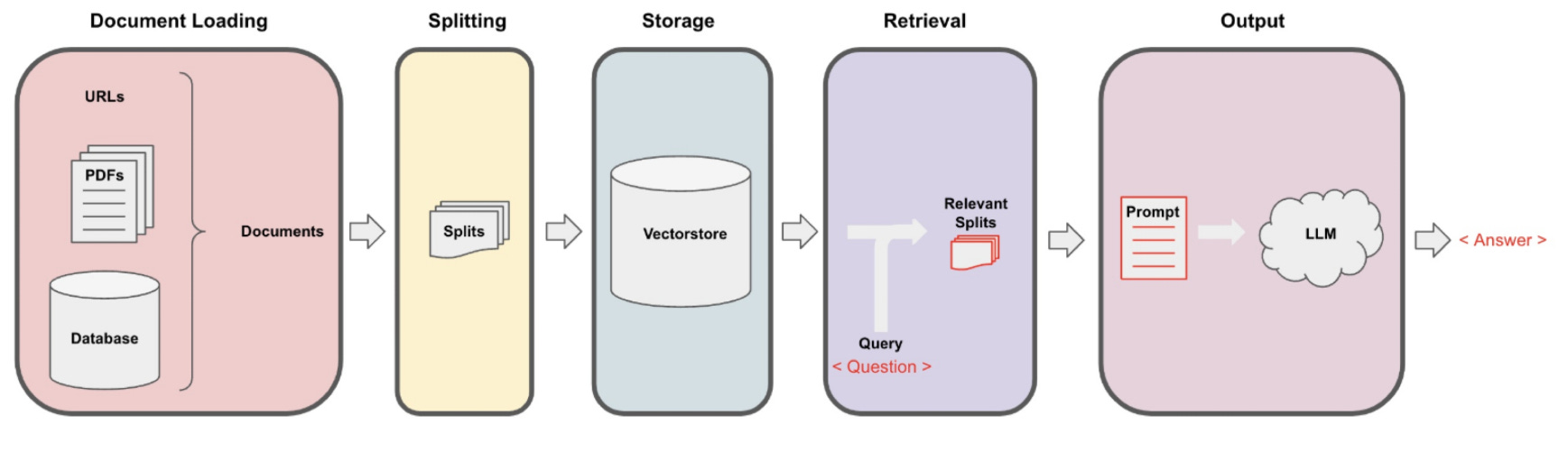
1️⃣ Load a PDF – Extracts text from a document using PyPDF2.
2️⃣ Chunk the Text – Uses RecursiveCharacterTextSplitter to break it into manageable pieces.
3️⃣ Create an In-Memory Vector Store – Uses Chroma with sentence-transformers/all-MiniLM-L6-v2 embeddings.
4️⃣ Run a Local LLM – Uses Ollama to power responses with deepseek-r1:1.5b.
5️⃣ FastAPI Endpoint – A /ask endpoint retrieves relevant chunks and generates concise answers.
What is RAG (Retrieval-Augmented Generation)?
Retrieval-Augmented Generation (RAG) is an AI technique that combines retrieval and generation to improve the quality and accuracy of responses from a language model.
1️⃣ Retrieve: The system searches for relevant documents or text chunks related to a user's query (e.g., from a PDF, database, or knowledge base).
2️⃣ Augment: The retrieved information is added to the LLM’s prompt to give it more context.
3️⃣ Generate: The LLM uses this enriched prompt to generate a more accurate and context-aware
What is FastAPI, LangChain, and Ollama?
FastAPI ⚡ – A high-performance Python web framework, perfect for building APIs.
LangChain 🧠 – A framework that helps connect LLMs with external data sources, like PDFs.
Ollama 🏗️ – A tool for running local LLMs on your machine without needing external API calls.
The Code
from fastapi import FastAPI, Query
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain.chains import RetrievalQA
from langchain_community.llms import Ollama
import PyPDF2
app = FastAPI()
def load_pdf(pdf_path):
with open(pdf_path, "rb") as f:
reader = PyPDF2.PdfReader(f)
return "\n".join([page.extract_text() for page in reader.pages if page.extract_text()])
pdf_text = load_pdf("mypdf.pdf")
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_text(pdf_text)
embedding_function = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
vector_store = Chroma.from_texts(chunks, embedding_function)
llm = Ollama(model="deepseek-r1:1.5b")
retriever = vector_store.as_retriever()
qa_chain = RetrievalQA.from_chain_type(llm, retriever=retriever)
@app.get("/ask")
def ask_question(question: str = Query(...)):
relevant_chunks = retriever.get_relevant_documents(question)
context = "\n\n".join([doc.page_content for doc in relevant_chunks])
prompt = f"Context:\n{context}\n\nQuestion: {question}\n\nAnswer:"
response = llm.invoke(prompt)
return {"question": question, "answer": response}
Installation and Setup
1️⃣ Install FastAPI and LangChain:
pip install fastapi langchain langchain_community pypdf chromadb sentence-transformers2️⃣ Install Ollama (for local LLMs) – Download it here
# Pull the TinyLlama model
ollama pull tinyllama
# List available models
ollama list Run
uvicorn rag_api:app --host 0.0.0.0 --port 8000 --reloadTest